
Tôi thường nhận được nhiều câu hỏi từ các bạn ở nhóm ngành khác IT, rất quan tâm đến lĩnh vực Data mining và Machine learning, rằng họ không biết nên bắt đầu từ đâu và như thế nào, có cần phải học lập trình không, có cần phải biết xác suất thống kê không. Tôi thường trả lời rằng:
Cũng giống như bạn chơi piano vậy, bạn không cần phải học nhạc lý để có thể chơi được nhạc cụ này nhưng nếu bạn không học những kiến thức căn cơ đó, bạn chỉ chơi được ở level trung bình, chỉ đủ thoả mãn sở thích, không đi xa và lâu dài được.
Lập trình và thống kê toán là một trong các kĩ năng không thể thiếu để tiến hành xây dựng các mô hình phân tích và nghiên cứu phức tạp. Tuy nhiên, những người không biết lập trình vẫn có thể sử dụng các sản phẩm phần mềm để phân tích và xử lý thông tin ở mức cơ bản một cách nhanh chóng mà không cần biết lập trình. Điển hình là các phần mềm spreadsheet quen thuộc như Excel (Windows), Libre office Calc (Linux), Numbers (Mac OS). Ta có thể làm các thống kê trên bảng dữ liệu (sum, count, avg, stddev, quantile, etc.), transform dữ liệu, load dữ liệu từ nhiều nguồn, visualize bằng các biểu đồ trực quan, thậm chí ta có thể làm data mining nếu ta cài thêm các plugin cho chúng.
Xu hướng tương lai mà các bạn sẽ nhận thấy đó là tất cả các tác vụ hiện nay mà Data Engineer/Analyst/Scientist đang làm mỗi ngày dần dần sẽ bị thay thế bởi các công cụ automation mạnh mẽ và trực quan, tiết kiệm chi phí thực nghiệm thay vì hàng tuần, tháng chỉ cần một hai ngày là hoàn tất. Đó cũng là mục đích tiến hoá của ngành công nghiệp, cố gắng tự động hoá các công việc tay chân vất vả, nhàm chán để nhường chỗ cho con người sáng tạo ở các vai trò khác quan trọng hơn. Bản thân tôi cũng thuộc type người lười công việc tay chân, không thích coding nhiều, cái gì automation được thì tôi rất muốn thử và sử dụng ngay.
Orange là một trong những công cụ Data mining nhắm đến mục tiêu tự động hoá này. Tôi nhận thấy đây là phần mềm dễ sử dụng nhờ giao diện nhỏ gọn, các toolbox được sắp xếp hợp lý mạch lạc, ai cũng có thể bắt đầu. Trong bài viết này, tôi sẽ tiến hành phân tích dữ liệu cũng như cài đặt một số hàm Machine learning quen thuộc để cho các bạn mới bắt đầu có thể hình dung vắn tắt một pipeline làm việc với dữ liệu thì sẽ như thế nào.
Bài viết sẽ bắt đầu bằng lược đồ overview của workflow mà bạn đang quan tâm rồi mới đi vào chi tiết từng thành phần. Trong quá trình hướng dẫn, những bước đã được trình bày, tôi sẽ lướt qua và chỉ đề cập đến các bước mới. Ở mỗi phần, tôi cũng dẫn link đến file Orange workflows (*.ows) để các bạn có thể download về tham khảo.
Orange làm được gì
Orange cung cấp cho người dùng tập các toolbox tinh gọn nhất giúp ta bắt tay ngay vào phân tích dữ liệu gồm:
Data: dùng để rút trích, biến đổi, và nạp dữ liệu (ETL process).

Visualize: dùng để biểu diễn biểu đồ (chart) giúp quan sát dữ liệu được tốt hơn.

Model: gồm các hàm machine learning phân lớp dữ liệu, có cả Neural Network gồm các hyper-parameter cơ bản để bạn xây dựng nhanh Deep learning thần thánh mà các fan Deep-learning based đang theo đuổi.


Evaluate: các phương pháp đánh giá mô hình máy học.

Unsupervised: gồm các hàm machine learing gom nhóm dữ liệu.

Others: các công cụ giúp ghi chú workflow ta đang làm việc.

Add ons: giúp bạn mở rộng các chức năng nâng cao như xử lý Big Data với Spark, xử lý ảnh với Deep learing, xử lý văn bản, phân tích mạng xã hội, etc. Đây có lẽ là điểm cộng của Orange vì khi sử dụng Weka phần mềm này không thể xử lý Big Data và tốc độ huấn luyện khá chậm.

Tiền xử lý dữ liệu
Đầu tiên, ta sẽ tiến hành ETL (Extract, Transform, Load) dữ liệu gồm các bước:
- Nạp dữ liệu horse-colic.csv.
- Quan sát bảng dữ liệu.
- Visualize dữ liệu.
- Chuẩn hoá dữ liệu và xử lý dữ liệu bị thiếu.
- Lưu dữ liệu đã xử lý.
File widget

Dùng để nạp dữ liệu từ các nguồn như .xlsx (Excel), .txt, .csv

Khi double-click vào biểu tượng File, ta sẽ mở dialog để xem và tinh chỉnh định nghĩa của bảng dữ liệu: nạp file dữ liệu ở đâu, thống kê sợ bộ số dòng, số cột dữ liệu, danh sách tên các thuộc tính (tên, kiểu dữ liệu, chức năng: feature, target, meta, skip) và mẫu dữ liệu quan sát.
Data table widget

Dùng để quan sát dữ liệu bảng biểu bằng cách nối File widget vào Data table widget. Khi double-click vào ta sẽ quan sát được dữ liệu.

Distribution widget

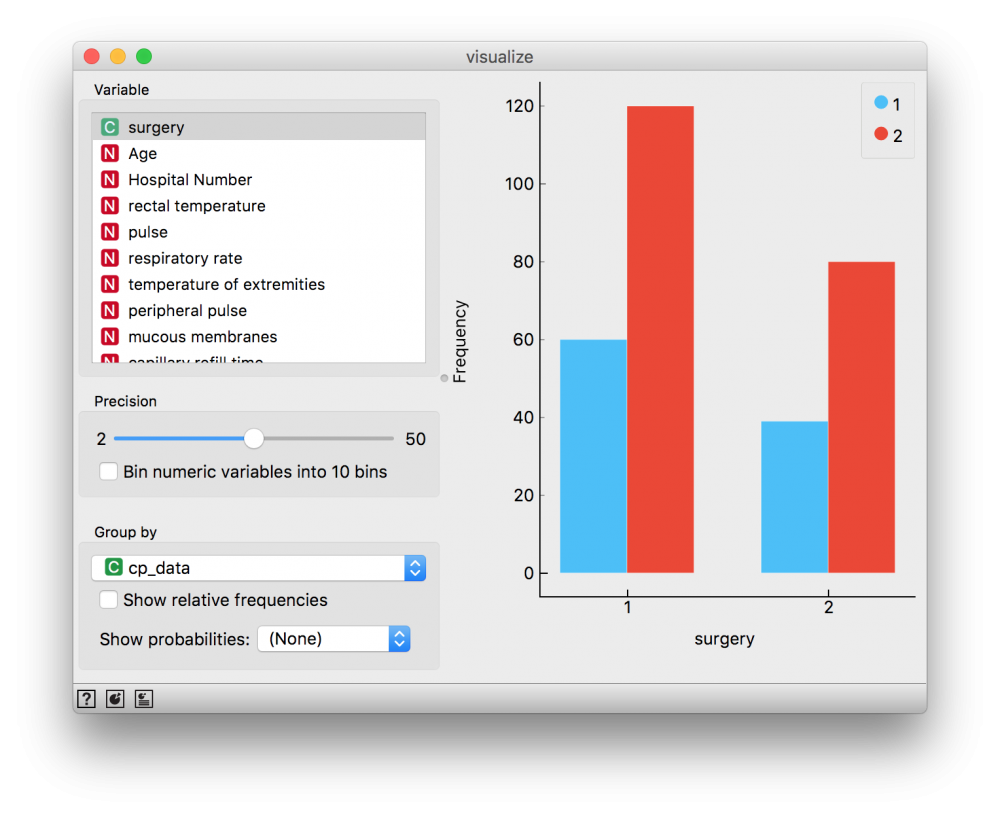
Dùng biểu diễn phân bố của một thuộc tính xác định. Ta nối File widget đến Distribution widget và double-click vào widget này để quan sát dữ liệu. Widget này tự động dùng bar-chart cho kiểu dữ liệu category và histogram cho kiểu dữ liệu số.


Preprocessing widget

Từ Data table widget, ta có thể thấy có 19.8% dữ liệu bị thiếu. Do đó, ta sẽ tiến hành tiền xử lý dữ liệu thông qua Preprocessing widget:
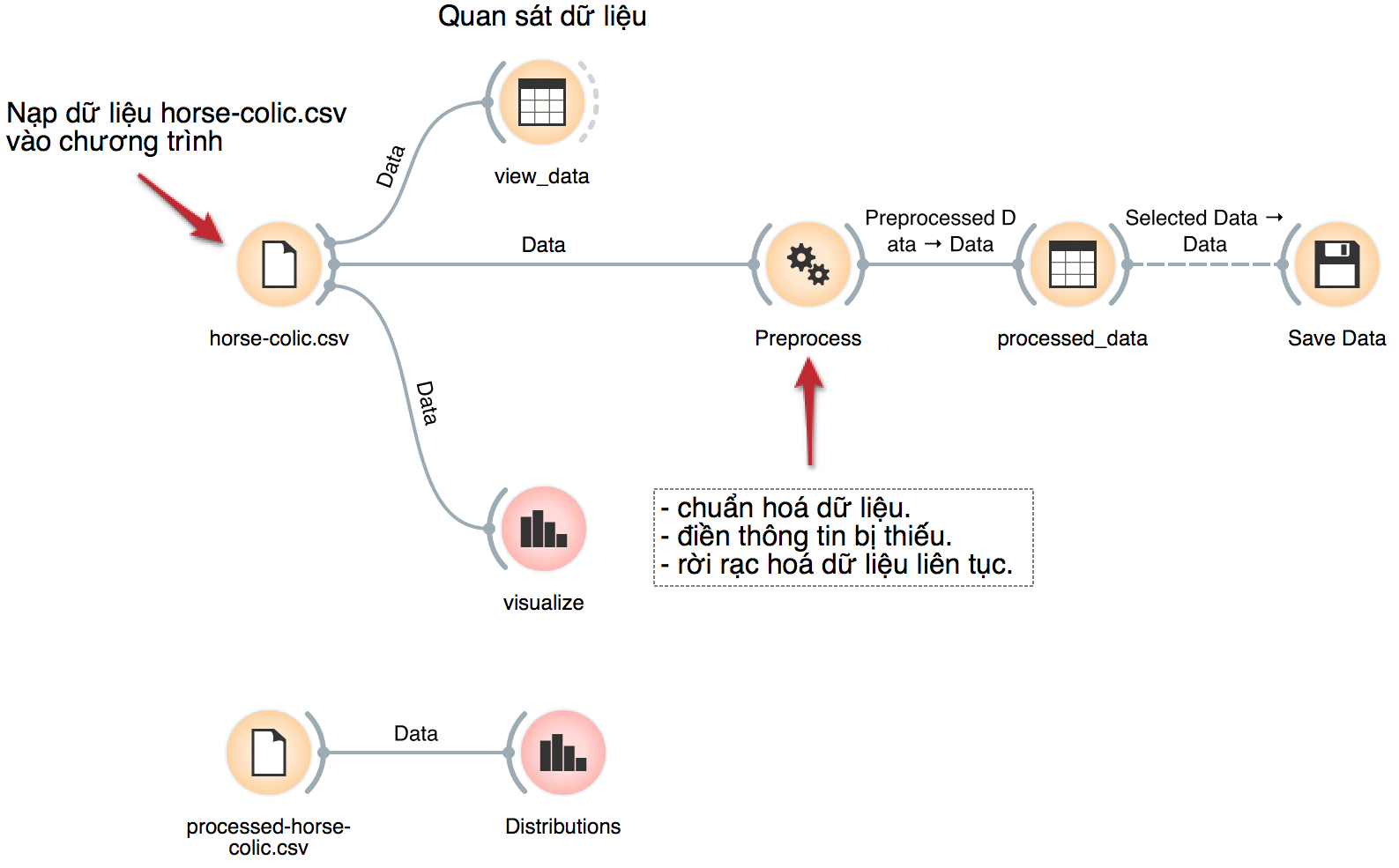
- Normalize Features: chuẩn hoá dữ liệu về đoạn 0-1
- Impute Missing Values: điền giá trị trung bình cho kiểu dữ liệu dạng số và giá trị phổ biến cho kiểu dữ liệu dạng category.
- Discretize Continuous Variables: chia giỏ dữ liệu 10 bins và mỗi bin có sai biệt đều nhau.
Save data widget
Dùng để lưu dữ liệu sau khi đã được xử lý. Lưu ý: ta cần chọn những dòng dữ liệu để lưu và bấm nút Save as để xác định địa chỉ lưu file.

Classification

Tiếp theo, ta sẽ vọc các hàm Machine learning classification gồm các bước sau:
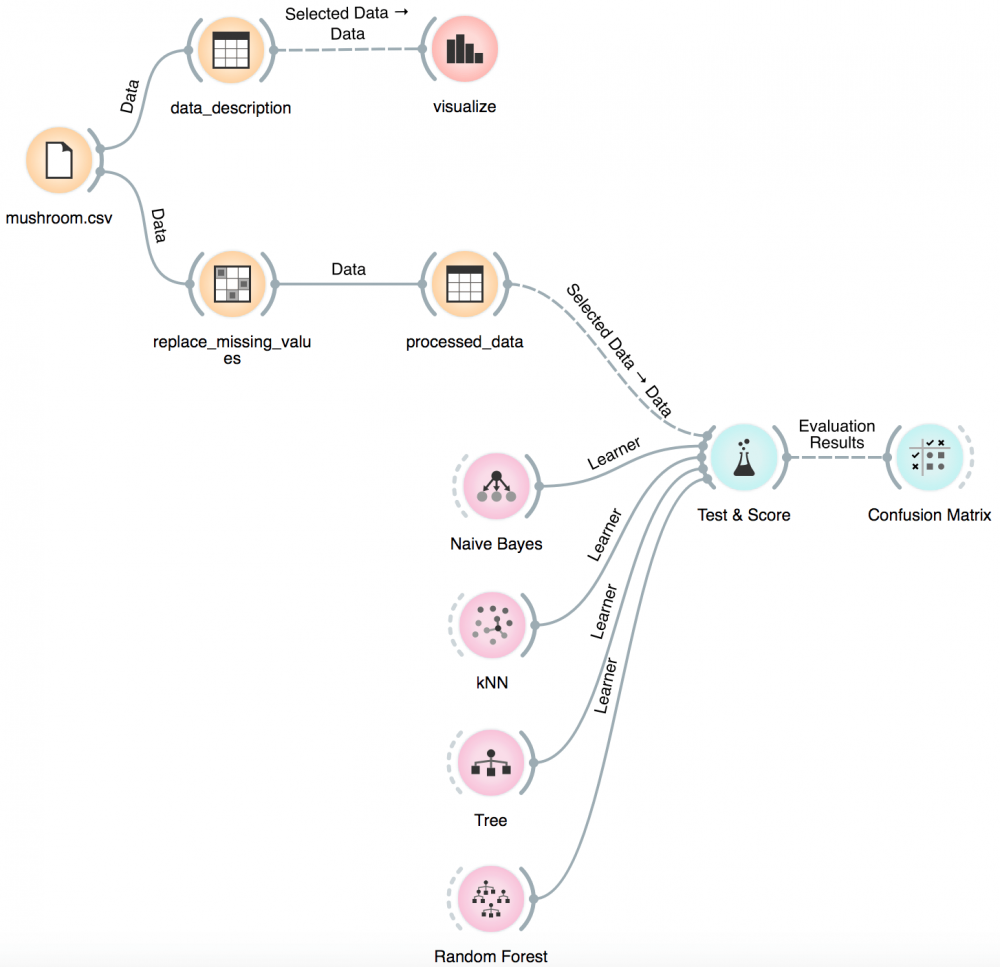
- Nạp dữ liệu mushroom.csv.
- Quan sát bảng dữ liệu.
- Visualize dữ liệu.
- Xử lý dữ liệu bị thiếu.
- Chuẩn bị các mô hình máy học: Naive Bayes, kNN, Decision tree, Random Forest.
- Test và đánh giá độ chính xác của các mô hình học.
Impute widget
Khác với Preprocessing widget, Impute widget dùng riêng cho tác vụ xử lý dữ liệu bị thiếu gồm các chiến lược:
- Don’t impute: không làm gì cả.
- Average/Most-frequent: điền giá trị trung bình đối với dữ liệu dạng số, điền giá trị phổ biến đối với dữ liệu dạng category.
- As a distinct value: điền giá trị được tự ta quy định.
- Model-based impute: sử dụng mô hình 1-NN để tìm mẫu dữ liệu na ná mẫu dữ liệu có thuộc tính bị thiếu.
- Random values: điền giá trị ngẫu nhiên thông qua thống kê của trường dữ liệu đó.
- Remove example: loại bỏ mẫu dữ liệu có giá trị bị thiếu.

Classification widget

Ta chuẩn bị các hàm phân lớp cùng với các thiết lập thông số tương ứng để huấn luyện như: Naive Bayes, kNN, Decision tree, Random Forest.


Test & Score widget

Dùng để đánh giá các mô hình máy học gồm các phương pháp như:
- Cross-validation: tạo ra 5 hoặc 10 folds cross validation, thường dùng để đánh giá trên mẫu dữ liệu nhỏ (1k-100k).
- Leave-one-out: tương tự như cross-validation nhưng chỉ lấy 1 instance ra để test, còn lại dùng để train.
- Random sampling: tách dữ liệu thành 2 phần ngẫu nhiên theo tỉ lệ train/test ví dụ như 70/30.
- Test on train data: dùng toàn bộ dữ liệu để train và test.
- Test on test data: chọn mẫu dữ liệu test để đánh giá.
Confusion matrix widget

Confusion matrix hiển thị số lượng instance dự đoán đúng và trật so với nhãn tập test.

Clustering
Tương tự, ta sẽ vọc các hàm Machine learning clustering gồm các bước sau:
- Nạp dữ liệu labor.csv.
- Quan sát bảng dữ liệu.
- Visualize dữ liệu.
- Xử lý dữ liệu bị thiếu.
- Chọn độ đo khoảng cách hợp lý.
- Tạo ma trận khoảng cách.
- Áp dụng mô hình gom nhóm: k-Means, Hierarchical clustering.
- Quan sát dữ liệu gom nhóm.
Distances widget

Tính khoảng cách giữa dòng/cột của tập dữ liệu cho trước gồm các metric:
- Euclidean: khoảng cách “đường thẳng” giữa 2 điểm.
- Mahattan: tổng trị tuyệt đối độ sai biệt giữa các thuộc tính.
- Cosine: tích vô hướng giữa hai vector (inner product).
- Jaccard: tỉ số giữa tập giao và tập hợp.
- Spearman/Spearman absolute: tương quan tuyến tính giữa các giá trị đã được rank
- Pearson/Pearson absolute: tương quan tuyến tính giữa các giá trị.

Distance map widget
Visualize khoảng cách giữa các điểm dữ liệu.

Distance matrix widget
Visualize khoảng cách giữa các điểm dữ liệu bằng ma trận khoảng cách. Mô hình clustering sẽ sử dụng ma trận này để huấn luyện.

Clustering data

Sau khi gom nhóm dữ liệu, ta có thể visualize trực tiếp hoặc chọn ra một vài điểm dữ liệu để quan sát xem mô hình gom nhóm có chính xác hay không.


Kết

Có bạn sẽ thắc mắc liệu tốn bao lâu để sử dụng được phần mềm này. Đối với bản thân tôi, gần như có thể sử dụng ngay lập tức. Trên dialog Welcome của orange có phân ra các mục Tutorials và Examples để bạn có thể tham khảo nhanh cách sử dụng. Tôi đã thử qua và đánh giá các ví dụ rất dễ hiểu, bạn có thể copy để phục vụ cho workflow của riêng mình.

Bạn có thể tham khảo thêm Weka, các phần mềm nâng cao hơn như KNIME, các Cloud computing service như Amazon, Google, Microsoft. Tuỳ mục đích và quy mô của dữ liệu, ta sẽ chọn bộ công cụ phù hợp nhất. Hy vọng Orange sẽ giúp các bạn không biết nhiều về lập trình nhưng hứng thú với công việc phân tích dữ liệu có thể thoả chí tò mò của mình cũng như giúp tăng tốc công việc hằng ngày của mình nhờ tiện ích automation đã được trình bày ở trên.





